수동 DNS( 도메인 이름 시스템 ) 센서의 사용 덕분에 연구원들은 시애틀에 기반을 둔 회사 Farsight 로부터 거의 실시간 DNS 데이터를 얻을 수 있었고 , 다양한 도메인에 대한 TXT 레코드에 대한 SPF 활동을 산출했다 .
원래 불균형 의료 데이터 처리를 위해 설계되고 scikit-learn 머신러닝 Python 라이브러리에 구현된 클래스 가중치 알고리즘을 사용하여 연구원들은 대기 중인 스팸 도메인의 4 분의 3 을 몇 분 안에 또는 작업 전에 감지할 수 있었다 .
논문에서는 다음과 같이 말한다 .
'TXT 레코드에 대한 단일 요청으로 스팸 캠페인이 시작되기 전에 스팸 도메인의 75% 를 감지한다 . 따라서 우리의 계획은 중요한 대응 속도를 제공한다 . 메일이 전송되기 전과 DNS 트래픽이 급증하기 전에도 우수한 성능으로 스패머를 탐지할 수 있다 .'
연구원들은 그들의 기술에 사용된 기능이 성능을 향상시키기 위해 기존 스팸 탐지 시스템에 추가될 수 있다고 주장한다 . 시스템은 문제에 대한 다양한 접근 방식에 이미 사용 중인 거의 실시간 DNS 피드에서 수동적으로 추론된 SPF 데이터에 의존하기 때문에 상당한 계산 오버헤드를 추가하지 않는다 .
이 문서의 제목은 패시브 DNS 및 SPF 를 사용한 스팸 도메인의 조기 감지이며 그르노블 대학교의 3 명의 연구원이 작성했다 .
SPF 활동
SPF 는 등록되고 승인된 IP 주소가 이메일을 보내는 데 사용되었는지 확인하여 이메일 주소 스푸핑을 방지하도록 설계되었다 .
이 SPF 의 예에서 'Alice' 는 'Bob' 에게 무해한 이메일을 보내고 공격자 'Mallory' 는 Alice 를 가장하려고 시도한다 . 둘 다 자신의 도메인에서 메일을 보내고 있지만 Alice 의 서버만 Alice 의 메일을 보내도록 등록되어 있으므로 Mallory 의 가짜 메일이 SPF 확인에 실패할 때 스푸핑이 저지된다 . 출처 : https://arxiv.org/pdf/2205.01932.pdf
다른 이메일 확인 방법에는 DKIM( 도메인키 식별 메일 DomainKeys Identified Mail) 서명과 DMARC( 도메인 기반 메시지 인증 , 보고 및 적합성 ) 가 있다 .
세 가지 방법 모두 인증 발신 도메인에 대한 도메인 등록 기관에서 TXT 레코드 ( 구성 설정 ) 로 등록해야 한다 .
스팸 및 화상
스패머는 이와 관련하여 ' 서명 행위 ' 를 나타낸다 . 그들의 의도 ( 또는 최소한 그들의 활동의 부수적 효과 ) 는 이러한 서비스를 판매하는 네트워크 공급자가 조치를 취할 때까지 대량 메일을 폭파하여 도메인 및 해당 IP 주소의 평판을 ' 소각 ' 하는 것이다 . 또는 관련 IP 주소가 인기 있는 스팸 필터 목록에 등록되어 현재 발신자에게 쓸모가 없게 만든다 ( 또한 IP 주소의 미래 소유자에게는 문제가 됨 ).
기회의 좁은 창 : SpamHaus 및 기타 다양한 모니터링 서비스에 의해 새로운 스팸 도메인이 금지되어 쓸모없게 되기까지의 시간 ( 시간 ).
도메인 위치가 더 이상 실행 가능하지 않으면 스패머는 필요에 따라 다른 도메인 및 서비스로 이동하여 새 IP 주소 및 구성으로 절차를 반복한다 .
데이터 및 방법
연구를 위해 연구한 도메인은 Farsight 에서 제공한 대로 2021 년 5 월에서 8 월 사이의 기간을 포함한다 . 영구 스패머의 방식과 일치하므로 새로 등록된 도메인만 고려했다 .
도메인 목록은 ICANN 중앙 영역 데이터 서비스 (CZDS) 의 데이터를 기반으로 작성되었다 . SURBL 및 SpamHaus 프로젝트의 블랙리스트 정보는 잠재적으로 문제가 있는 새 도메인 등록을 거의 실시간으로 식별하는 데 사용되었다 . 작성자는 스팸 목록의 불완전한 특성으로 인해 양성 도메인이 실수로 대량 메일의 잠재적 소스로 분류될 수 있다는 점을 인정한다 .
수동 DNS 피드에서 발견된 새로 등록된 도메인에 대한 DNS TXT 쿼리를 캡처한 후 유효한 SPF 데이터가 있는 쿼리만 유지되어 알고리즘에 대한 실제 정보를 제공했다 .
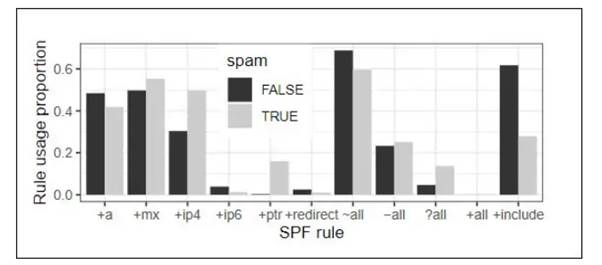
SPF 에는 여러 가지 유용한 기능이 있다 . 새 문서에 따르면 ' 양호한 ' 도메인 소유자는 +include 메커니즘을 가장 일반적으로 사용하지만 스패머는 ( 현재 사용되지 않는 ) +ptr 기능을 가장 많이 사용한다 .
스패머의 SPF 규칙 사용량과 표준 사용량 비교 .
+ptr 조회는 보내는 메일의 IP 주소를 해당 IP 와 호스트 이름 ( 예 : GoDaddy) 간의 연결에 대해 존재하는 모든 레코드와 비교한다 . 호스트 이름이 검색되면 해당 도메인은 SPF 레코드를 참조하는 데 처음 사용된 도메인과 비교된다 .
스패머는 +ptr 의 명백한 엄격함을 악용하여 더 신뢰할 수 있는 조명으로 자신을 나타낼 수 있다 . 실제로는 대규모 +ptr 조회를 수행하는 데 필요한 리소스로 인해 많은 공급자가 확인을 완전히 건너뛸 수 있다 .
요컨대 스패머가 ' 폭발 및 소각 ' 작전이 시작되기 전에 기회의 창을 확보하기 위해 SPF 를 사용하는 방식은 기계 분석으로 유추할 수 있는 특징적인 시그니처를 나타낸다 .
스팸 도메인에 대한 특징적인 SPF 관계 .
스패머는 종종 매우 가까운 IP 범위와 리소스로 이동하기 때문에 연구원들은 IP 범위와 도메인 간의 상관 관계를 조사하기 위해 관계 그래프를 개발했다 . 그래프는 SpamHaus 및 기타 소스의 새로운 데이터에 대한 응답으로 거의 실시간으로 업데이트될 수 있으므로 시간이 지남에 따라 더욱 유용하고 완전해진다 .
연구원들은 다음과 같이 말한다 .
' 이러한 구조에 대한 연구는 잠재적인 스팸 도메인을 강조할 수 있다 . 우리 데이터 세트에서 수십 개의 도메인이 동일한 [SPF] 규칙을 사용하고 대부분이 스팸 블랙리스트에 나타나는 [ 구조 ] 를 발견했다 . 따라서 나머지 도메인은 아직 탐지되지 않았거나 아직 활성 스팸 도메인이 아닐 가능성이 있다고 가정하는 것이 합리적이다 .'
결과
연구원들은 50 시간 동안 SpamHaus 및 SURBL 에 대한 접근 방식의 스팸 도메인 탐지 지연 시간을 비교했다 . 그들은 식별된 스팸 도메인의 70% 에 대해 자체 시스템이 더 빨랐다고 보고했지만 식별된 스팸 도메인의 26% 가 다음 시간에 상업 블랙리스트에 나타났음을 인정했다 . 도메인의 30% 는 패시브 DNS 피드에 나타났을 때 이미 블랙리스트에 있었다 .
저자는 단일 DNS 쿼리를 기반으로 한 F1 점수가 79% 라고 주장하지만 Exposure 와 같은 경쟁 방법은 일주일의 예비 분석이 필요할 수 있다 .
그들은 관찰한다 :
' 우리의 체계는 도메인 수명 주기의 초기 단계에 적용할 수 있다 . 수동 ( 또는 능동 ) DNS 를 사용하여 새로 등록된 도메인에 대한 SPF 규칙을 가져와 즉시 분류하거나 해당 도메인에 대한 TXT 쿼리를 감지하고 구체화할 때까지 기다릴 수 있다 . 회피하기 어려운 시간적 특징을 사용한 분류 .'
그리고 계속 :
'[ 우리의 ] 최고의 분류기는 스팸 도메인의 85% 를 탐지하고 가양성 비율을 1% 미만으로 유지한다 . 도메인 SPF 규칙의 내용과 그 관계만 분류하고 DNS 트래픽을 기반으로 한 기능을 회피하기 어렵다는 점에서 탐지 결과가 괄목할 만하다 .
' 분류기의 성능은 단일 TXT 쿼리 ( 수동적으로 또는 능동적으로 쿼리됨 ) 에서 수집할 수 있는 정적 기능만 제공되더라도 높은 상태를 유지한다 .'
새로운 방법에 대한 프레젠테이션을 보려면 아래에 포함된 비디오를 확인하라 .
VIDEO